热门标签:
eukaryotic
英文/拉丁名称(Latin Name):eukaryotic 中文名称(Chinese Name):真核的,真核生物的
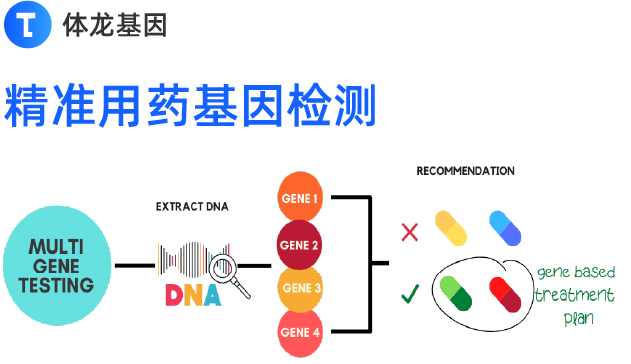
检测流程
样本采集注意事项
为您解决烦忧 - 24小时在线 专业服务
免费咨询基因检测相关问题
chemi- 的中文含义:化学
hepatocuprein 的中文含义:肝铜蛋白,超氧化物歧化酶
aglycon(e) 的中文含义:糖苷配基
paedoparthenogenesis 的中文含义:幼体单性生殖,幼体孤雌生殖
isotropous 的中文含义:①等向弯的②各向同性的